Searching for third-party details in a microservice architecture
How do you enforce a pure domain model, while allowing clients to search for information related to, but not included in, your domain model?

I am Software Engineer, turned Data Engineer, that aims at bridging the gap between business and software. I enjoy functional programming due to testability and maintainability - I enjoy distilling problems utilizing Domain-Driven Development, lower-case agile, and a ton of other principles.
Motivation
When you are developing a domain model, you want it to be as concise as possible - only containing abstractions related to the problem you are trying to model. This, however, can become an impediment if you want to expose a search engine where you can input any string, and gets any match back, even on information that is only indirectly related to your model - How does your service know if a match exists, if the info isn't directly stored in your domain model?
This exact case was something we experienced at my prior place of employment, and a coworker(I miss you!) and I came up with a great solution. I'll eventually reuse it in my Kanban project project and wanted to explain how it works.
The core problem
I want to be able to search for one or more search terms and get Cards back that match the search terms.

One might search for word(s) that is contained in the title of the card. This is easy to implement, as the title is part of our domain - our API will simply return any matches that contain that string. What if we want to search for the name of the author? Our system is going to use a third-party authorization provider. That means the microservice won't actually know the name of the author. They'll simply know that the author is a user with id 75adff81-269e-412c-a1c8-fbbfb998b5e8.
User story
When I search for a full or subpart of an author's name or part of a title, I want all cards that match all query terms, so I can find the cards I am looking for
Bad solution(s)
You can skip this part if you just want our solution.
Growing your domain model
You could simply argue "Well maybe the author's name is part of the domain model!". But where does that logic end? We'll quickly have to model things only indirectly related. What if we create custom integrations with different version control systems, and want to enable searching on pull-request names (or descriptions)? Are they then also part of the domain? Suddenly your domain is growing and coupled with the models of third-party systems. More coupling. More to maintain.
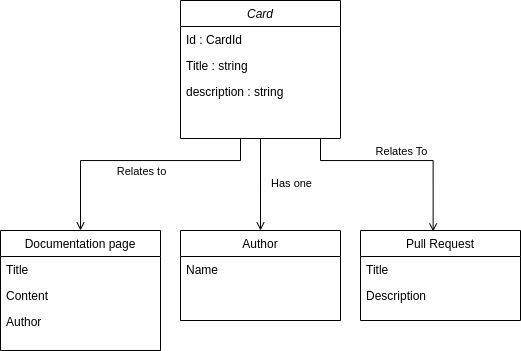
We'll also have to update our domain model whenever the code of third-party systems changes (which is bad for a number of reasons. Go read the DDD book). There will be large data movements all the time.

Transient requests
Rather than bringing third-party systems to us, we could bring the query to the third party.
Upon receiving a query request, we simply query all the third-party systems and then use that to filter the cards. Or simply go through each card and fetch the author (etc) and check if it's a match. Yes, some requests will be done a bunch of times, but we could always use caching.
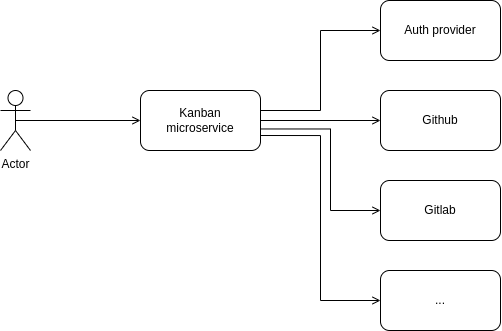
Great! our domain model is quite pure. But wait. One of the many requests to the third-party systems suddenly throws an error.. and the whole search fails.

The issue above is also that the system's ability to do searching suddenly is coupled directly with the availability of the third-party system. What if it's down? what if our cache is cold? We might end up DDoS'ing the third-party system if we have enough different cards. They might also not appreciate it. There is also the whole thing that the requests will be rather slow.
Code Opinion had a great video that is related (mainly the part about queries):
Transient requests are generally speaking not the best in microservice architectures.
Another issue is where to place this logic. Suddenly either the repository will have dependencies on a bunch of third-party systems, or you have to move searching into a service of sorts. It has a bunch of problems.
A Good solution.
This might not be the ideal solution, and I'd love to hear a comment down below if I missed something, or if one of the other solutions is better.
Going back to the user story. It contains a term that I want to add to our ubiquitous language: keyword. Rather than storing specific pieces of data, what we really care about is that some card matches some keyword.
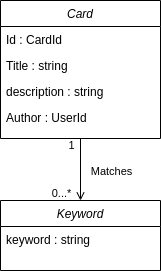
This makes it easier to reason about searching in our domain because it's less tightly bound to any specific third-party model. That an actual list of keywords might include the name of the author isn't something our model necessarily cares about.
These keywords, however, have to be created. For that, we need a function (or interface if you have a OO language - it's the same). We called this concept a keyword provider.
type KeywordProvider = Card -> Keyword list
This gives us the benefit of being able to split the different keywords up into different chunks of code. We can create a very simple keyword provider, that gives us the keywords that reside in the domain:
let DomainKeywordProvider card = [
Keyword (card.Id.ToString ());
Keyword card.Title;
Keyword card.Description
]
(I hope F# isn't too scary. this is just a function that takes a card as input and returns a list of keywords.)
What we will eventually have is a wide range of different KeywordProviders. Some that fetch from our Auth system. Maybe from Github. What do I know? It's quite easy to create new ones. But then eventually we want to get all keywords for a given card, from all sources. For that, we can define a CompositeKeywordProvider:
let CompositeKeywordProvider (providers : KeywordProvider list) (card : Card) =
providers |> List.collect (fun provider -> provider card)
(👻 scary F#: It takes a list of KeyWordProviders and returns a function that takes a card and returns the keywords all the keyword providers return for that card)
Which can then be used like this (Assume we also defined an AuthorKeywordProvider):
let provider = CompositeKeywordProvider [
DomainKeywordProvider;
AuthorKeywordProvider
]
We now need to call this provider. But how/where? If we simply call it whenever we get a request (i.e edit a card), that won't do. We are back at the same issues with the transient requests.

We instead created an asynchronous worker that fetches keywords. This decoupled the generating of keywords from both writing data as well as searching.
This isn't enough, as the third-party data might change without us knowing. A user might change their name, which will then create inconsistencies. We decided on accepting a model based on Eventual consistency.

The icing on the cake was to utilize a decorator pattern, which triggered the keyword worker whenever a card changed. This made it possible to instantly search for anything you just created.
One might also want any changes to third-party data to instantly be reflected in searches, however, this is less critical in our cases. If it was a big issue, one would have to have an event-driven architecture throughout the ecosystem - that would enable us to run the keyword worker whenever a "user name updated" event was sent. We didn't have such an event-driven architecture and settled on updating the keywords based on a scheduled job.
Conclusion
Is this the best solution? not sure. It solved the problems we had and enabled us to have a great user interface with search functionality. From a development perspective, it's easier to add support for new keywords. When we expanded our domain model, it was easy to add more searching too. We and the stakeholders were happy (I was a bit proud), and it helped evolve the ubiquitous language and model to add the keyword concept.
Edit:
I shared the article with one of my smart friends. He pointed out that, what we ended up building was basically a Search indexing engine. In that terminology, we should not use the term /keyword/ but rather /index/. We could refactor it. That would probably be the right thing to do. Whether you want to do that, is up to you.




