API First? No, thank you! Schema-first, please!
Working API-first is great, but I'd argue technological advances makes Schema-first even greater.

I am Software Engineer, turned Data Engineer, that aims at bridging the gap between business and software. I enjoy functional programming due to testability and maintainability - I enjoy distilling problems utilizing Domain-Driven Development, lower-case agile, and a ton of other principles.
I've developed a lot of APIs, and have been working API-first, with rough steps like the following:
Write a very rough API in whatever framework, returning sample responses
Generating a schema from the API, i.e. with Swashbuckle
Sharing the schema with developers of a web client, so they can start working on a consumer
Implement the actual implementations of the API.
This has a bunch of benefits; you have a small increment, you can get feedback on the API design early, and you don't block the development of any consumer. It's great.
Recently I was advised, in a project at work, to start by defining the API schema instead. It seemed stupid and tedious to write a bunch of yaml by hand.
I gave it a try at work, and have done so again in a hobby project. It's great!
What is an API schema?
Schema or specification - I'd probably use those interchangeably. It's a document of sorts, that specifies all the endpoints you have, what they can return, and how you interact with them. You have probably already experienced one artifact of them; namely an API documentation, either with Swagger or Redocly.
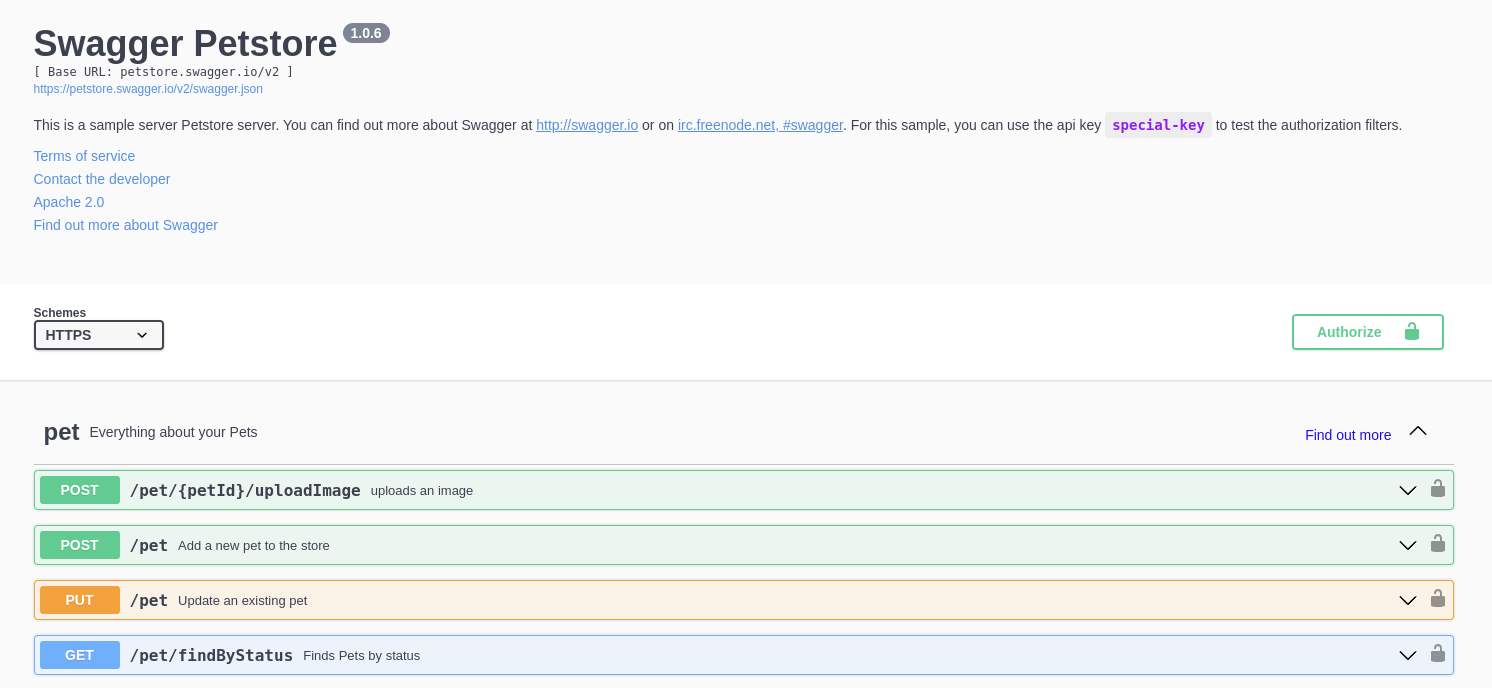
That's one cool aspect of it; you can have a nice interactive visualization/documentation.
Another neat benefit is code generation. I'll get back to that.

There are a bunch of different neat tools and possible artifacts. The most widely used format is the OpenAPI specification, developed by the awesome OpenApi Initiative, originally based on the Swagger Specification. gRPC also utilizes a format (in *.protofiles) to specify the structure of communication.
Previously, when working API-First, I would generate an OpenAPI specification based on the defined API. Tools like Swashbuckle does this behind the scenes. Django REST Framework does the same, and I imagine a wide range of tools do too.
So why not use the API to generate a specification? Why would you write YAML by hand?

Why write boring YAML by hand
I've worked with UXers (Which is not UI!), in a wide range of jobs - and a key practice they always do is to work with Low-fidelity prototypes. You want something simple, where people don't overthink specific details too much, and you have to spend less time on it; it is easier for someone to criticize a YAML file, than an API you spend a week on writing - and you'll be less pissed when they say "Wait we want our api to be level 3 REST" (Tbh, you might be pissed anyway, that is very holier-than-thou)(There is a substantial risk I'll love level 3 rest in the future, and you are welcome to mock me).
Furthermore, you will enable a consumer to write their clients even earlier on.
And you'll be able to write your API specification with real-time input from the people developing a client. Pair programming, baby! We've actually done this in the past quite often; in a planning session, we would loosely verbally agree on which endpoints we'd need, and the expected payloads. Not sure why we never wrote it down in a formal specification language.
There is also the benefit of having a source-controlled "contract", where you agree on the communication between devices. It can be discussed, read, and updated in its own right.
Oh and lastly, there is the whole code generation perspective (That I'll get to soon!)

How do you write it?
The first time, we sat two people in a video call, screen sharing, as you would do in a pair programming session. One person writing. We had some great discussions; "I would prefer CQRS", "Could we reuse this Dto?" or "Hmm I would need X to solve this". It evened out a few issues we might have gotten later.
Yesterday, when I had to set up an API for another project, we didn't have time to get together. Instead, I wrote the specification and sent a pull request and it was reviewed with a person that visualized the spec in a VSCode extension. And due to it being a language with a formal definition, we were able to set up a CI pipeline that does linting with redocly-cli.
He also used some code generation to visualize the models in a class diagram, which made it easier to reason about.

Another neat thing (not to jump on a hype train) is you can utilize LLMs (ChatGPT and similar) to write parts of it - or help you. In my example, I had written a bunch of domain logic, and I had this annoying big part of data classes I had to write into the schema. Chatty to the rescue:
Code generation
Okay, okay - Code generation.
So it's a formal specification that defines how a given server and client should communicate. It has typing etc. That makes it possible to generate code that follows that specification. Obviously not the actual implementation, but using tools like openapi-generator, which (as of writing) has 66 different client generators and 67 different server generators. It can also generate PlantUML code/diagrams. It's pretty neat.
I created a reproducible script for a project yesterday, that can regenerate my server if our specification is to change (new features, changes, etc.), which means that if I run it, my code won't compile, and if I don't implement all the new/changed endpoints. The auto-generated code is then isolated, making it easy to import and utilize as wanted. The same can be done on the client side.
What's the catch?
A bunch of the code generators are a bit dated. They don't seem to have much contribution as of late. I tried to use the f# giraffe generator, which hasn't been update for 2 years and therefore doesn't seem to work well with the newest versions of F#, dotnet, or Giraffe. I've previously experienced similar issues with other generators. That is obviously a pain.
I am also a pedantic perfectionist developer. I ended up using a C# aspnet generator (A cool thing about F# is that I can define one project in C# and the rest in F#). It does work, but I am not entirely happy about the outcome; one issue is that it uses C# DataContracts, not records, meaning I can, in theory, generate invalid Dtos. Another issue is that it utilizes the IActionResult return type on the API calls, which means I can, with no compile-time errors, return a different Dto than the schema defines.
These aren't inherently issues with OpenAPI, but more issues with difficult-to-maintain projects and ASP.nET.
These issues could be fixed by a (pedantic) developer (like me) that contributes time and energy to a great open-source project. I have fixed the IActionResult in prior projects - it requires some boilerplate but does work. Similarly, I could update the giraffe generator, or write one for f# ASP.NET (I consider doing so), but finding the time is difficult.
Finally, I would add that working schema-first does have a bunch of benefits even without code generation. You have a formal agreement, similar to data contracts, which is all the hype in the data world.
Conclusion
Spec-First brings numerous advantages. It feels "weird" at first, yet the benefits it offers, such as improved change tracking, streamlined discussions, and enhanced convenience as a long-term artifact, are substantial in my perspective.
Even with the drawbacks regarding community size which, you and I can help improve, I believe Spec-First has the potential to enhance the velocity, design, and communication of future APIs.



